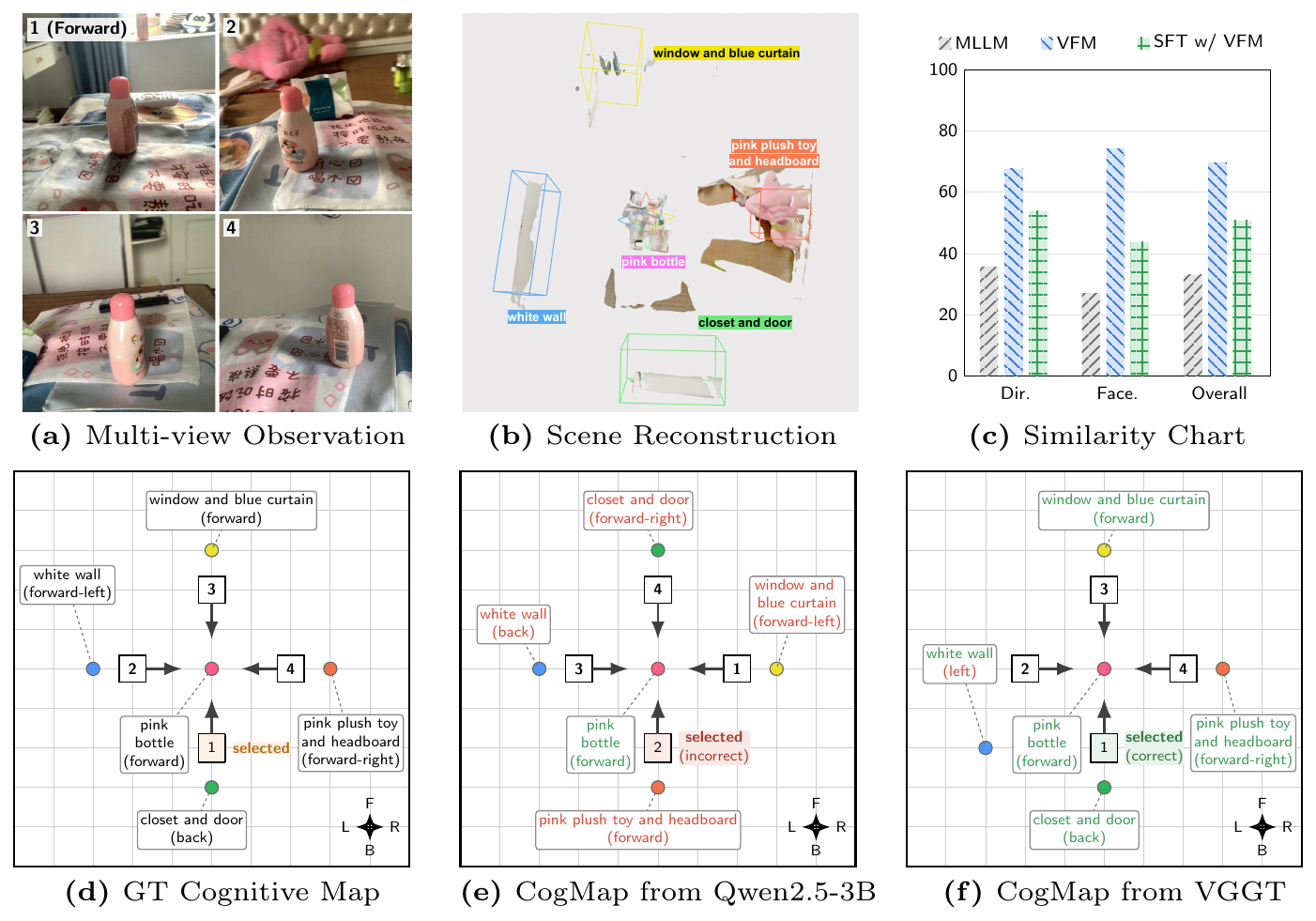
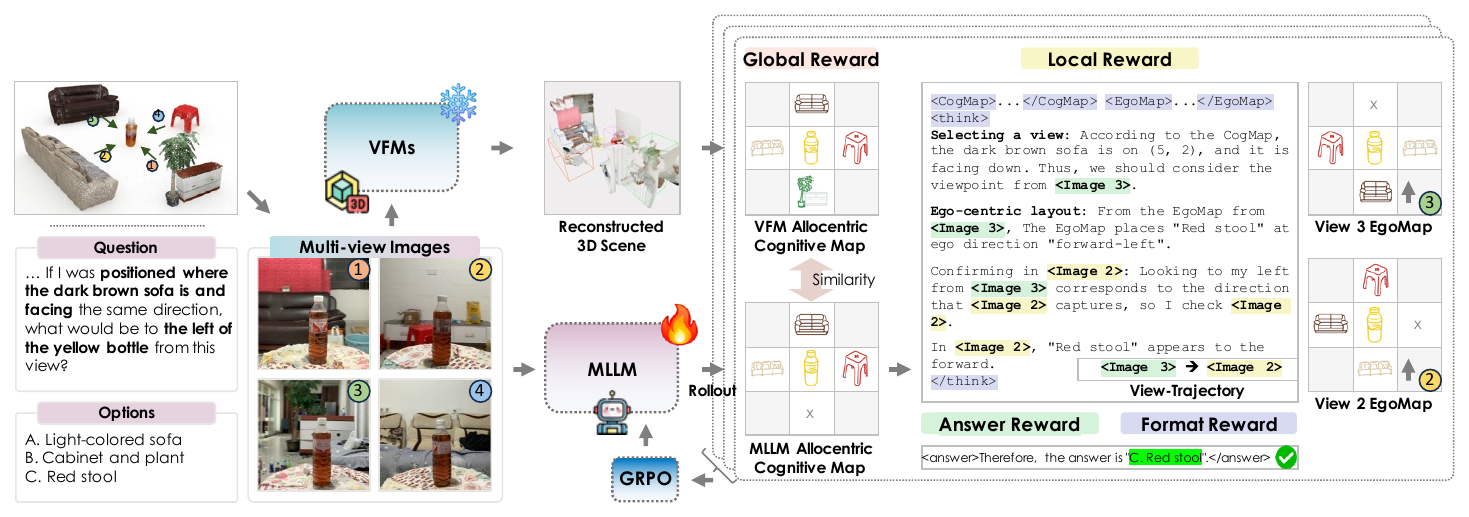
The idea in one figure
Sparse Rewards Guess. Dense Rewards Check.










Show the full teaser figure from the paper
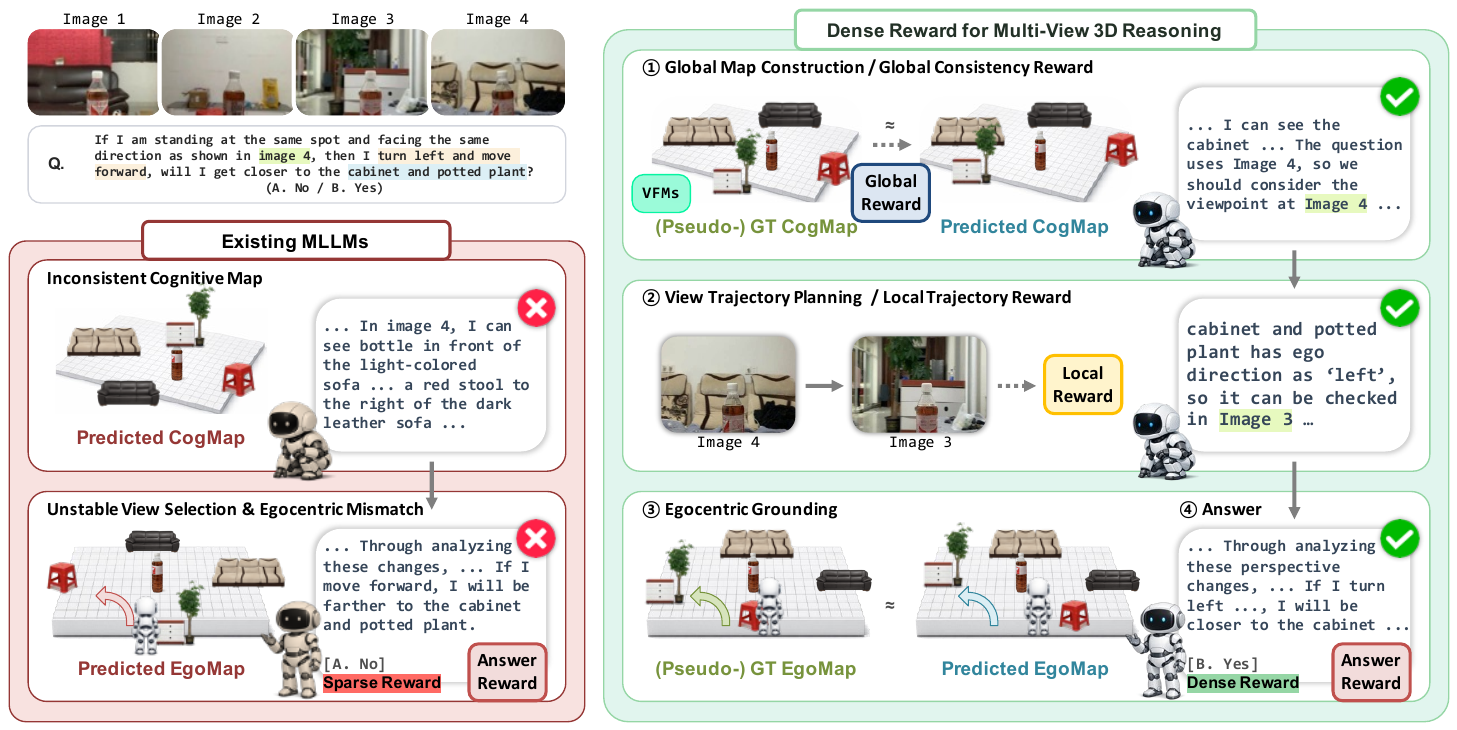
Figure 1. Overview of DR-MV3D. Sparse, answer-level supervision (left) builds inconsistent cognitive maps and misreads egocentric directions, so the model lands on a wrong answer even when the reasoning looks plausible. DR-MV3D (right) supervises the process with dense, verifiable rewards: a global reward aligns the predicted allocentric map with a geometry-consistent target from a frozen VFM, and a local trajectory reward guides ordered viewpoint selection.